LLM(3)transformer
GPT(Generative Pre-trained Transformer)是由 OpenAI 提出的生成式预训练语言模型,其核心架构基于 Transformer。GPT 通过在大规模文本数据上进行预训练,学习语言的统计规律,然后通过微调应用于各种自然语言处理任务,如文本生成、翻译和问答等。
一、Transformer 架构概述
Transformer 是一种基于自注意力机制的神经网络架构,专为处理序列数据而设计。它由编码器(Encoder)和解码器(Decoder)组成,每个部分都包含多个相同的层。
transformer架构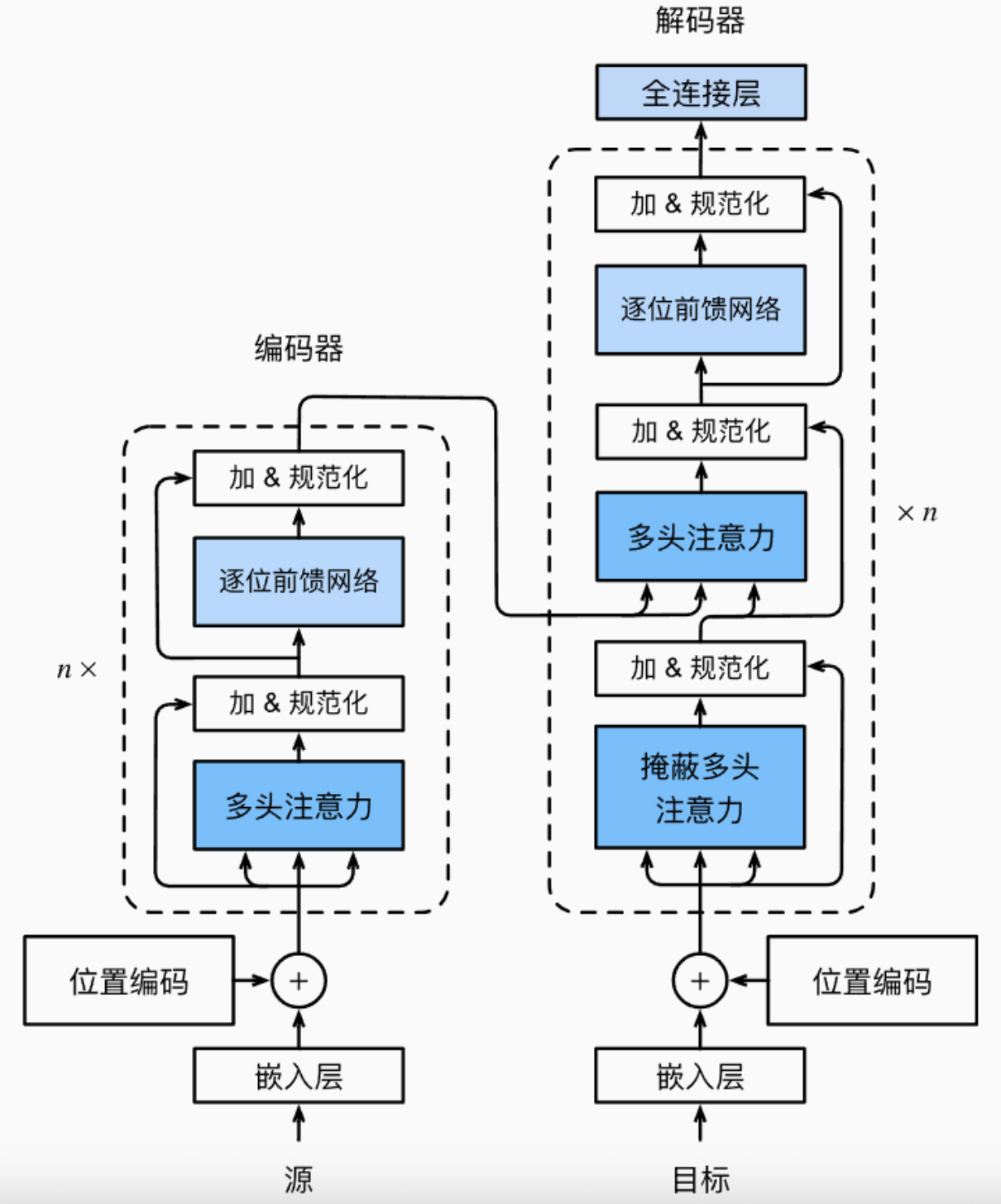
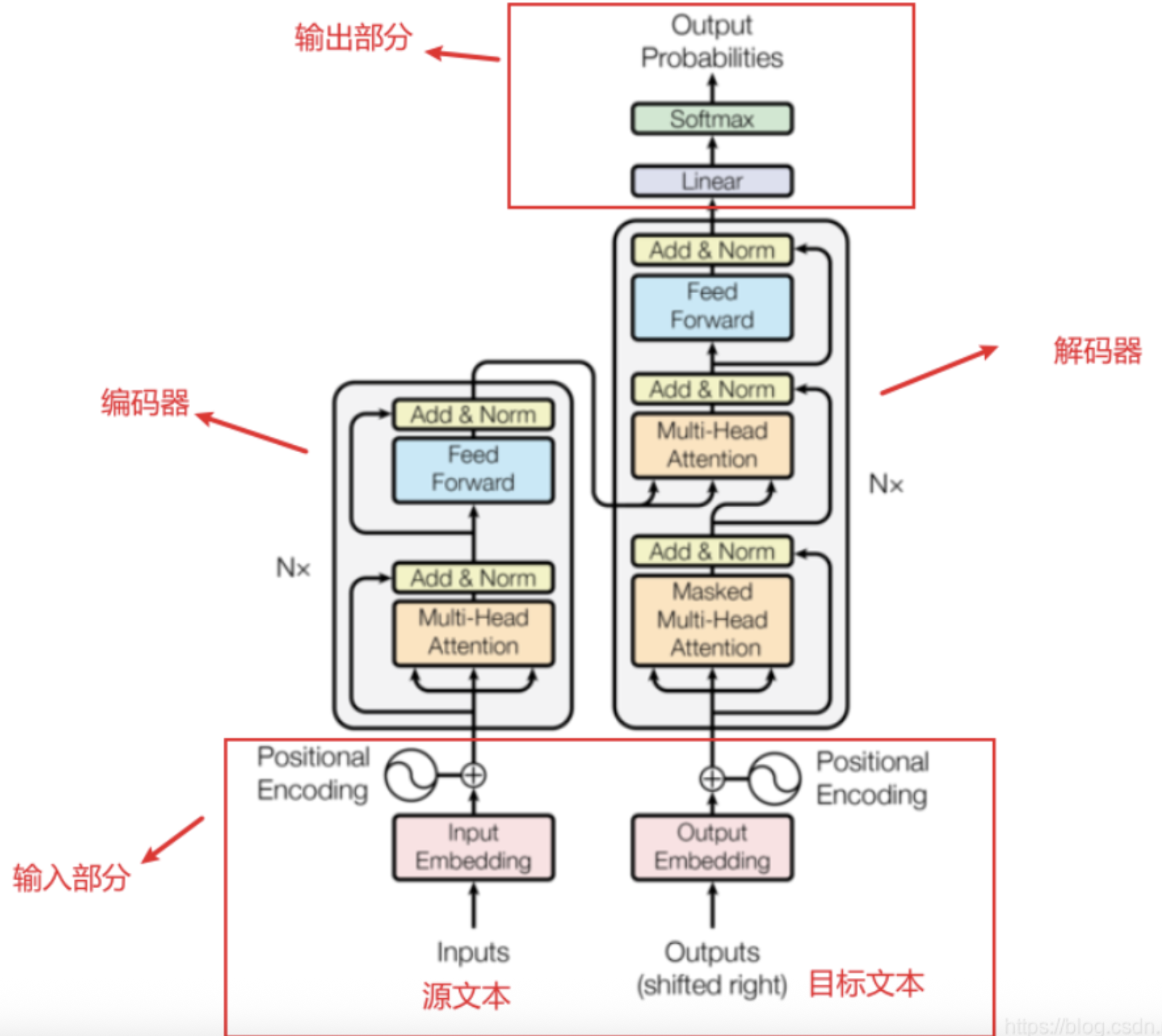
1. 自注意力机制(Self-Attention)
自注意力机制允许模型在处理每个位置的输入时,考虑序列中所有其他位置的信息,从而捕捉长距离的依赖关系。 (提取关键信息,存在依赖/映射关系)
2. 多头注意力(Multi-Head Attention)
通过并行地执行多个自注意力操作,模型可以从不同的子空间中学习信息,提高了模型的表达能力。
3. 前馈神经网络(Feed-Forward Neural Network)
每个编码器和解码器层中都包含一个前馈神经网络,用于进一步处理注意力机制的输出。
4. 残差连接和层归一化(Residual Connection & Layer Normalization)
为了缓解深层网络中的梯度消失问题,Transformer 在每个子层后添加了残差连接,并进行层归一化,促进了模型的训练稳定性。
5. 位置编码(Positional Encoding)
由于 Transformer 不具备处理序列顺序的能力,因此引入位置编码以提供位置信息,帮助模型理解词语的顺序。
二、GPT 的关键原理
GPT 模型仅使用 Transformer 的解码器部分,采用自回归的方式进行训练,即在给定前文的情况下预测下一个词。其主要特点包括:
1. 预训练与微调
- 预训练:在大规模未标注文本数据上进行训练,学习语言的统计规律。
- 微调:在特定任务的数据集上进行微调,使模型适应具体的应用场景。
2. 自回归生成
GPT 通过自回归方式生成文本,即每次生成一个词,并将其作为输入继续生成下一个词,直到生成完整的文本序列。
3. 掩蔽自注意力(Masked Self-Attention)
为了防止模型在训练时看到未来的信息,GPT 在自注意力机制中引入了掩蔽操作,确保每个位置只能关注当前及之前的位置。
三、GPT 与 Transformer 的关系
虽然 GPT 基于 Transformer 架构,但它仅使用了解码器部分,并进行了特定的调整以适应语言建模任务。
四、总结
GPT 是一种强大的语言模型,通过预训练和微调的方式,能够在多种自然语言处理任务中表现出色。其基于 Transformer 架构,利用自注意力机制有效地捕捉文本中的依赖关系,实现高质量的文本生成。