sre基础篇-3切入点SLI、SLO
SLI/SLO
- SLI(service level indicator)服务等级指标
- 指标来衡量系统稳定性
- SLO (service level objective) 服务等级目标
- 设定稳定性目标(99.999 …)
扣款请求接口,状态码非5xx的比例(SLI),大于99.5%(SLO)表示系统稳定
系统中常见监控指标
- 系统层
- cpu使用率、mem使用率、load负载、磁盘使用率、磁盘IO、网络IO…
- 应用服务器层
- 端口存活、JVM堆内存使用情况及GC状况、OOM自动转出堆文件
- 应用运行层
- 请求状态码、请求时延、应用QPS、TPS、连接数…
- PAAS层
- mysql、mongodb、redis、kafka、ceph…
- 数据层
- 批处理、流式任务、吞吐率
- 业务层
- 在线用户、注册用户、下单数…
SLI指标选择原则:
- 1.选择能标识主体是否稳定的指标,而非主体本身的指标
- 2.优先选择业务服务对象的指标(电商用户体验,政务流畅性、便捷性)
google sre valet
在谷歌的Site Reliability Engineering(SRE,站点可靠性工程)中,VALET 是一个用于定义和衡量服务级别目标(SLO)的框架和指标集合。它的全称是 Volume, Availability, Latency, Errors, Tickets,代表了五个关键的运营指标,用于帮助团队评估服务的健康状况和可靠性。以下是对 VALET 的简要介绍:
Volume(流量)
表示服务的请求量或使用量,通常以每秒请求数(requests per second)或类似单位衡量。它反映了系统的负载情况,是评估服务性能的基础。Availability(可用性)
衡量服务正常运行的时间比例,通常以百分比表示(例如 99.9% 的可用性)。这是 SRE 中最核心的指标之一,直接关系到用户体验。Latency(延迟)
表示服务响应请求所需的时间,通常关注特定百分位数(如 99th percentile latency,即 99% 请求的响应时间)。低延迟是提供良好用户体验的关键。Errors(错误)
跟踪服务中发生的错误率,例如失败的请求比例。这有助于识别潜在问题并确保系统稳定性。Tickets(工单)
表示因服务问题生成的手动工单或警报数量。这是衡量运维负担的指标,目标是尽量减少人工干预,通过自动化解决问题。
valet例子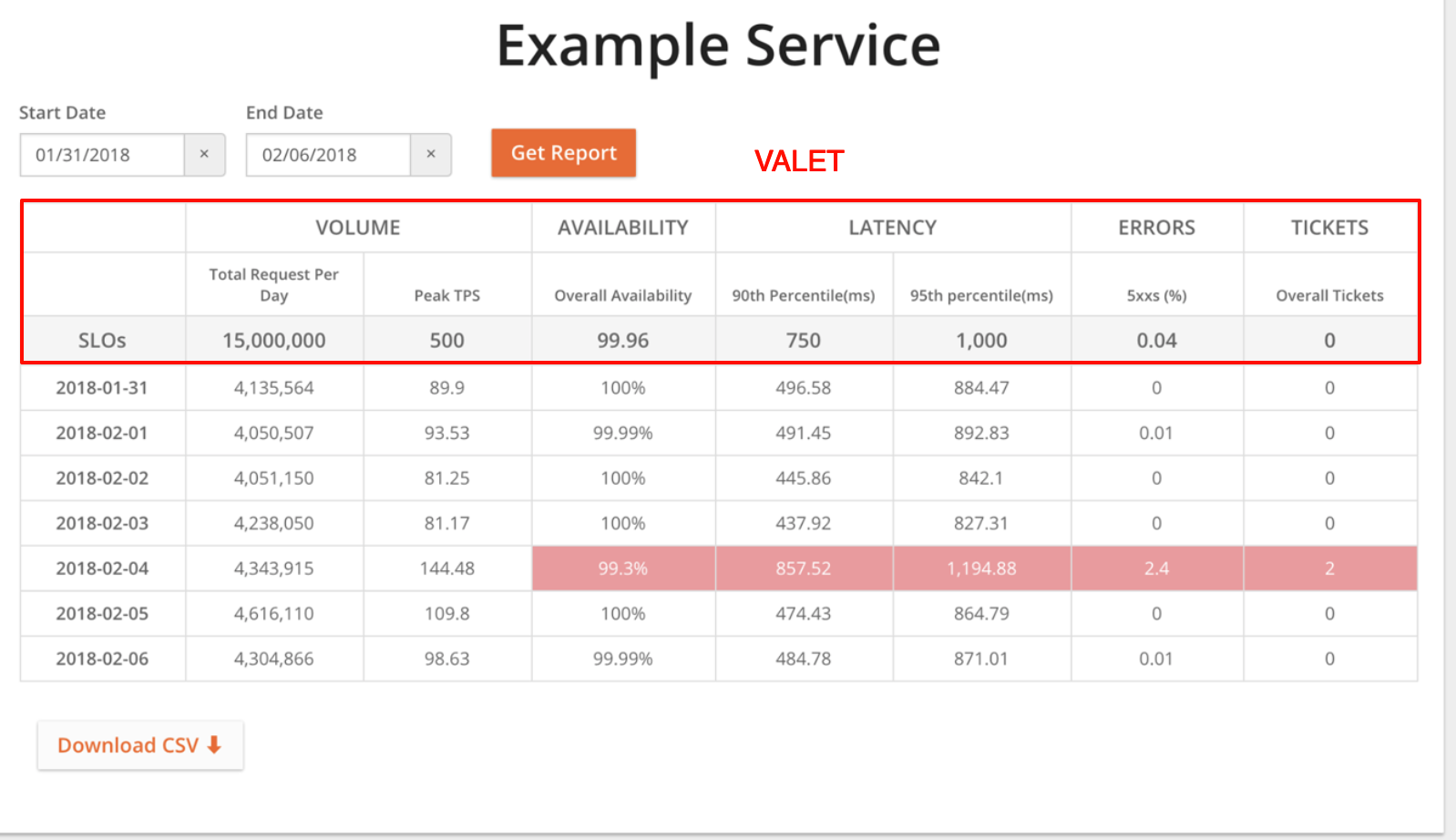
VALET 的作用
VALET 提供了一个简单而全面的框架,帮助 SRE 团队和开发团队围绕服务的可靠性展开协作。它不仅用于监控和报告,还可以指导错误预算(Error Budget)的制定。通过这些指标,团队能够明确服务的优先级,平衡新功能开发与系统稳定性的需求。
在实践中的应用
在谷歌SRE的案例研究(如《The Site Reliability Workbook》中提到的 Home Depot 的实践)中,VALET 被用来设计仪表盘、自动化数据收集,并推动整个组织采用 SLO 文化。通过将复杂的系统运行状况简化为这五个维度,团队可以快速诊断问题并采取行动。