sre基础篇-2系统可用性
sre是一个系统化工程,来保障系统稳定性(提示MTBF,降低MTTR),系统可用性跟系统稳定性强相关,稳定性目的就是减少系统故障、异常运行状态的发生,提高系统可用运行的时间占比(提高MTBF)。
系统可用性(system availability)
- 可用性维度
- 时长维度: availibility = uptime / (uptime + downtime)
- 请求维度 availibility = sucessfule request / total request
时长维度
时长维度,总的来说是从故障角度出发对系统稳定性进行评估。
- 衡量指标
- 异常状态码
- 衡量目标
- 异常占比
- 影响时长
- 持续时间
系统可用性几个9对着表
- 90% 一个9 36.5d
- 99% 两个9 3.65d
- 99.9% 三个9 8.76h
- 99.99% 四个9 52.56m
- 99.999% 五个9 5.26m
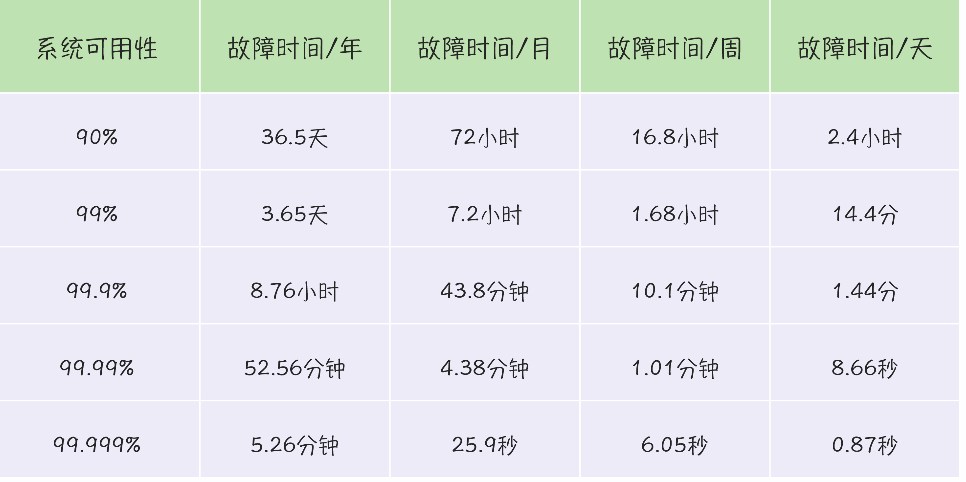
时长维度来衡量系统稳定性,颗粒度不够精细。
请求维度
请求维度,是从成功请求占比角度,对系统稳定性进行评估。
一般是saas,对系统要求高的网站
- 请求维度
- 衡量指标: 请求成功率
- 衡量目标: xx%系统运行稳定(阈值定义)
- 统计周期: xxx-过去时间段内
故障一定意味着不稳定,不稳定,并不意味着一定有故障发生。
稳定性考虑因素
- 成本因素
- 越多的9意味着付出的成本和代价会更高,投入更多的资源来保障高可用、冗余资源、主备、多活、一地三中心
- 业务容忍度
- 核心业务,要求越多的9
- 外围业务,适当的9
- 当前系统稳定性状况
- 定一个合理的标准比一个更高的标准更加重要(强化信心、积极性,逐步提高标准)
sre稳定性是系统整体运行状态,不是仅仅关注故障状态下的稳定性,系统任何异常都应该纳入到稳定性的评估范畴中。
可用性监控维度
系统可用性是指系统在一段时间内能够正常工作并提供服务的能力。
系统可用性的监控是多维度的,不仅仅是硬件的健康状况,还包括应用、网络、安全、性能等方面。通过全方位的监控,可以实时发现问题并采取措施,确保系统能够持续稳定地提供服务。
1. 硬件监控
- 服务器状态:监控服务器的健康状况,包括CPU、内存、硬盘、网络接口等的使用情况。
- 存储设备:监控磁盘空间、读写速度、磁盘健康状态等,确保没有磁盘故障或空间不足导致服务中断。
- 网络设备:监控路由器、交换机、负载均衡器等设备的工作状态,确保网络设备正常运作。
2. 软件与应用监控
- 应用程序状态:监控关键应用的运行状态,查看是否有崩溃、挂起或响应缓慢等问题。
- 错误日志监控:定期检查系统和应用的日志,发现是否有错误、警告或异常日志,及时解决潜在问题。
- 数据库健康监控:监控数据库连接数、查询响应时间、锁等待时间等,避免数据库瓶颈影响系统可用性。
3. 性能监控
- 响应时间:监控系统对用户请求的响应时间,确保系统在承受负载时能够快速响应。
- 吞吐量:监控系统的处理能力,包括每秒处理的请求数量等,确保系统能够在高负载下保持稳定。
- 负载均衡:监控负载均衡器的状态,确保请求能够合理分配到不同的服务器,避免单点过载。
4. 网络监控
- 带宽利用率:监控网络带宽的使用情况,确保没有带宽瓶颈导致的访问速度下降或服务不可用。
- 延迟和丢包率:监控网络的延迟和丢包情况,及时发现网络故障或瓶颈。
- 网络连接数:监控外部或内部网络的连接数量,确保连接数不过载,避免网络故障影响系统可用性。
5. 安全监控
- 防火墙与安全设备:监控防火墙、入侵检测系统(IDS)、入侵防御系统(IPS)等的运行状况,防止外部攻击或内部安全漏洞影响系统可用性。
- 漏洞扫描与补丁管理:定期检查系统和应用的漏洞,并及时应用补丁,避免安全漏洞导致服务中断。
6. 用户体验监控
- 用户反馈:收集用户的反馈和投诉,了解实际用户体验,及时发现潜在的系统不可用问题。
- 端到端监控:监控从用户端到服务器端的完整流程,包括页面加载速度、应用响应时间等,确保用户在任何情况下都能获得流畅的服务体验。
7. 冗余与备份监控
- 高可用性架构:监控多机房、集群、负载均衡等高可用架构的健康状态,确保在单点故障时不会影响整体系统可用性。
- 备份与恢复:定期检查系统备份是否正常进行,确保数据能够在灾难恢复时迅速恢复,避免服务中断。
8. 自动化监控和报警
- 自动化检测:利用自动化工具实时检测系统状态,并在发现问题时快速反应。
- 报警机制:设置合适的阈值,一旦某项指标超出正常范围,立即触发报警,确保问题能够及时得到处理。
9. 定期测试与演练
- 容错能力测试:定期进行故障演练,模拟系统故障或灾难恢复的场景,确保系统能够在突发情况下快速恢复。
- 压力测试:进行高并发、压力测试,确保系统能够应对大量用户请求,不会因负载过重导致服务中断。